

Der Fehler passiert in nahezu jedem zweiten Erstgespräch, das wir führen: Unternehmen kommen mit einer klaren Frage, „Welche KI sollen wir einsetzen?”, und überspringen dabei die Frage, die vor allen anderen steht: „Sind unsere Daten gut genug dafür?”
Die Antwort ist selten bequem. In der Praxis heißt sie oft: erst die Datenbasis aufbauen, dann die KI einführen. Nicht umgekehrt.
Dieser Artikel zeigt, warum die Datenstrategie der KI-Strategie vorausgehen muss, welche typischen Muster wir in mittelständischen Unternehmen beobachten, und wie ein strukturierter Einstieg aussieht, der nicht mit einem teuren Pilotprojekt endet, das nach drei Monaten eingemottet wird.
Warum Datenstrategie vor KI-Strategie kommt
Was eine Datenstrategie wirklich bedeutet
Eine Datenstrategie ist kein Glossar und kein Technologieprojekt. Sie beantwortet drei Fragen:
- Welche Daten haben wir? Bestandsaufnahme aller relevanten Datenquellen (ERP, CRM, MES, IoT, Dateiablagen)
- Wie verlässlich sind sie? Bewertung von Vollständigkeit, Aktualität, Konsistenz und Zugriffsrechten
- Was wollen wir damit erreichen? Klare Verknüpfung zwischen Daten und den Geschäftszielen, die KI unterstützen soll
Ohne diese drei Antworten ist jede KI-Strategie eine Spekulation.
Das Symptom: Showcases statt Produktivbetrieb
Wir beobachten in unseren Projekten immer wieder dasselbe Muster: Ein produzierendes Unternehmen mit rund 180 Mitarbeitenden investiert 40.000 Euro in einen KI-Piloten zur Produktionsoptimierung. Nach acht Wochen steht ein funktionierender Prototyp. Die Datengrundlage basiert auf drei Monaten manuell bereinigter Excel-Exporte, weil die Systeme nicht direkt angebunden werden konnten. Nach drei Monaten wird der Prototyp nicht weiterentwickelt, die Datengrundlage ist zu instabil, die Wartung zu aufwendig.
Das Problem ist fast nie die KI. Es sind die Daten.
Typische Datenprobleme, die KI-Projekte abwürgen:
- Stammdaten, die in ERP und CRM unterschiedlich gepflegt werden
- Reports, die sich widersprechen, weil sie aus unterschiedlichen Quellen gespeist werden
- Historische Daten, die nicht in der Form vorliegen, die das Modell braucht
- Zugriffsrechte, die nicht geklärt sind und das Projekt verzögern
„Wir haben doch ein BI-System.”, Ja. Und trotzdem widersprechen sich Ihre drei wichtigsten Reports. Genau das ist das Problem.
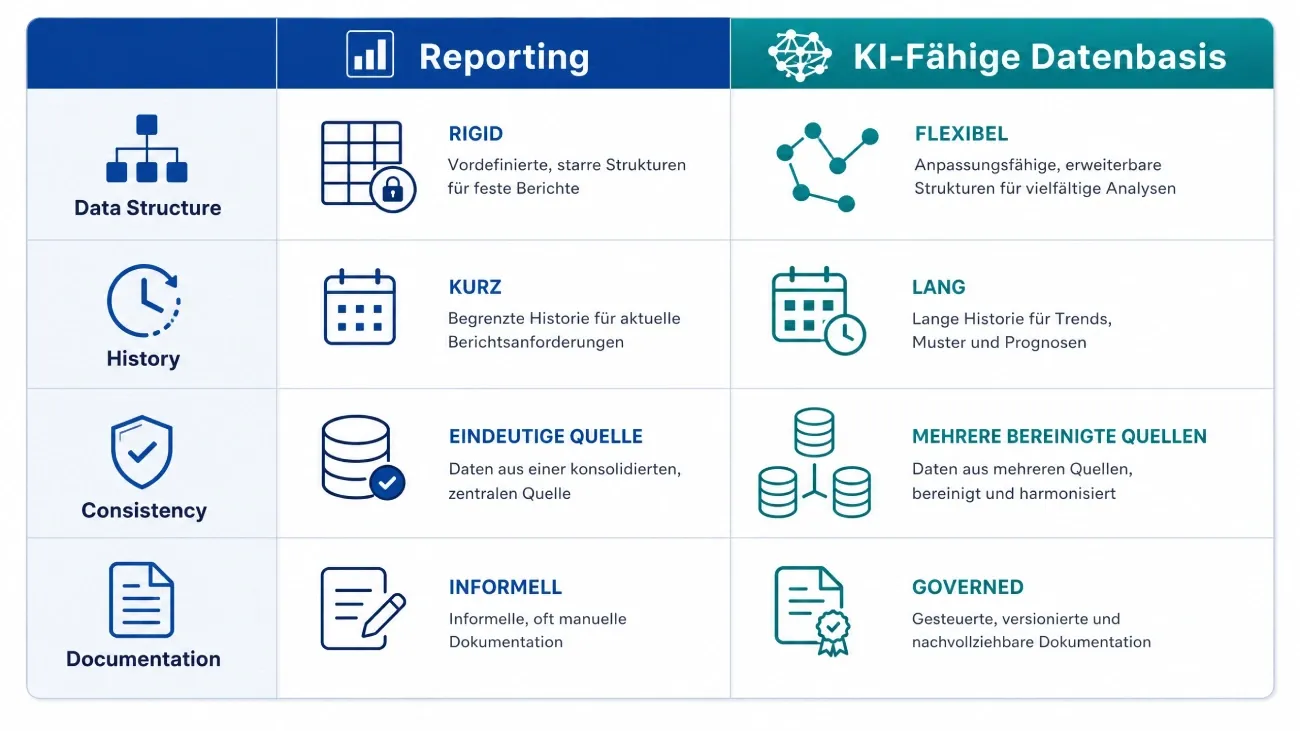
Der Unterschied zwischen Reporting und KI-Fähigkeit
Viele mittelständische Unternehmen haben bereits Reporting-Strukturen. Dashboards laufen, KPIs werden berechnet. Das ist ein guter Ausgangspunkt, aber es reicht nicht für KI.
Reporting beantwortet Fragen, die Sie vorher definiert haben. KI-Systeme verarbeiten Daten auf Basis trainierter Modelle, aber auch sie brauchen strukturierte, konsistente und relevante Daten, um zuverlässige Ergebnisse zu liefern. Ohne saubere Datengrundlage entstehen Fehlallokationen, Halluzinationen und falsche Schlussfolgerungen.
Laut einer McKinsey-Studie zu KI-Implementierungen im Produktionssektor (2024) scheitern rund 56 % aller industriellen KI-Piloten an mangelnder Datenqualität, nicht an der Algorithmik.
Das Mittelstands-Datenparadoxon: Warum Datenqualität systematisch unterschätzt wird
Unsere Erfahrung aus über 15 Projekten im Mittelstand zeigt ein wiederkehrendes Muster: Unternehmen unterschätzen systematisch den Aufwand für Datenqualität, weil:
- Bestehendes Reporting als Beweis für Datenreife gilt. Die Existenz von Dashboards suggeriert Stabilität, die tatsächlich nicht da ist
- Datenqualität als IT-Thema verstanden wird, nicht als Business-Thema. Die Konsequenzen landen beim Controlling, nicht beim CIO
- Pilotprojekte ohne Datenvalidierung starten. Die Enttäuschung kommt post-mortem, nicht vorher
Das Ergebnis: Datenprojekte werden nach dem ersten gescheiterten KI-Piloten entweder abgebrochen oder mit massiv höherem Budget neu gestartet.
Was stattdessen funktioniert: Ein ehrliches Daten-Readiness-Assessment vor dem ersten Investitionsentscheid. Kosten: 1–2 Wochen. Ergebnis: Eine realistische Einschätzung, ob und wann die Datenbasis KI-ready ist.
Der typische Weg ins Scheitern, und wie er vermeidbar ist
Muster 1: Tool-first, Strategy-later
Unternehmen kaufen ein KI-Tool oder beauftragen einen Berater mit einer Technologieempfehlung, ohne vorher die eigenen Daten zu bewerten. Das Ergebnis: ein Werkzeug, das auf einer instabilen Grundlage steht.
Was stattdessen funktioniert: Datenbewertung vor Toolauswahl. Erst verstehen, was die Daten hergeben. Dann prüfen, welches Tool dazu passt.
Muster 2: Die falsche Priorisierung
„Wir brauchen jetzt KI, die Daten kommen dann schon.” Dieses Muster endet fast immer gleich: Das Pilotprojekt wird verschoben, verzögert, oder liefert Ergebnisse, die das Vertrauen in KI nachhaltig beschädigen.
Was stattdessen funktioniert: Ein klarer Zwischenschritt „Datenbasis bewerten und aufbauen” als eigenständiges Projekt. Nicht als Vorstufe, die man nebenbei mitmacht.
Muster 3: Silodaten werden ignoriert
ERP, CRM, MES, Excel, SharePoint, E-Mail-Anhänge, in vielen Mittelständlern liegen die relevanten Daten verteilt über fünf bis zehn Systeme. Jedes System hat seine eigene Logik. Keines kommuniziert mit dem anderen.
Was stattdessen funktioniert: Ein strukturiertes Datenqualitäts-Audit als erster Schritt. Nicht alle Daten auf einmal, sondern die Daten, die für die relevantesten Use Cases gebraucht werden. Wie sich daraus ein konsolidierter Single Point of Truth entwickeln lässt, zeigt unser ausführlicher Case.
Datenstrategie aufbauen, Ein pragmatischer 4-Schritte-Ansatz
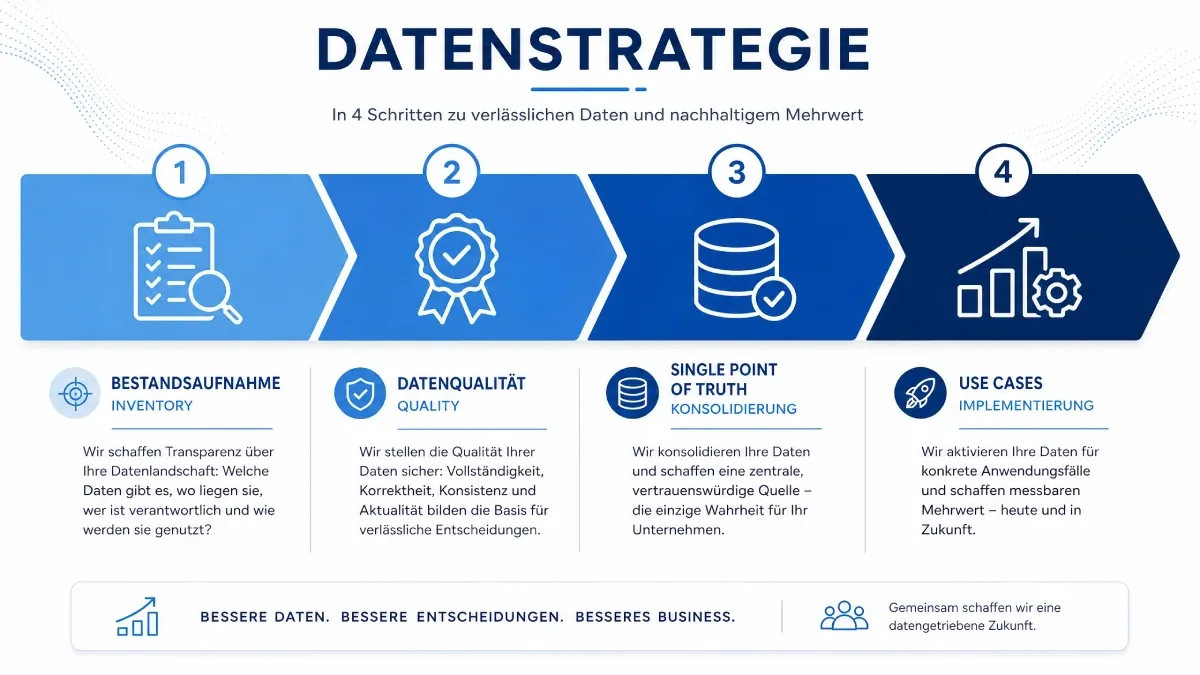
Schritt 1, Bestandsaufnahme: Was haben wir wirklich?
Listen Sie alle Datenquellen auf, die für Ihre relevantesten Geschäftsprozesse relevant sind. Nicht was installiert ist, sondern welche Daten tatsächlich fließen. Typische Kandidaten im Mittelstand:
- ERP-System (SAP, Microsoft Dynamics, Infor): Stammdaten, Bestände, Aufträge, Finanzdaten
- CRM (Salesforce, HubSpot, Dynamics CRM): Kundendaten, Kommunikationsverläufe, Vertriebspipeline
- MES / Produktionssysteme: Maschinendaten, Zykluszeiten, Qualitätsdaten, OEE-Kennzahlen
- IoT-Sensoren: Temperatur, Druck, Energieverbrauch, Zustandsdaten
- Office-Systeme: E-Mails, Dokumente, Projektmanagement-Tools
- Excel-Dateien: Oft die am schwersten zu ersetzende Datenquelle
Fragen Sie sich ehrlich: „Wenn wir ein konsistentes Bild aller dieser Daten bräuchten, wie lange würde es dauern, das herzustellen?” Wenn die Antwort „Monate” oder „unbekannt” ist, haben Sie Ihre erste Priorität.
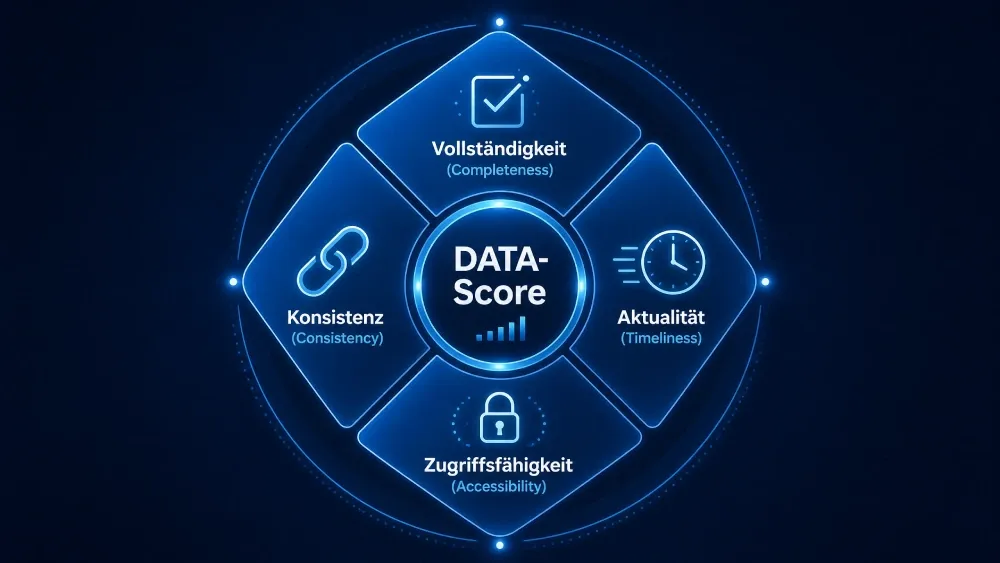
Schritt 2, Datenqualität bewerten: Der DATA-Score
Nicht alle Daten sind gleich wichtig. Für die relevantesten Use Cases bewerten wir die Datenqualität anhand von vier Dimensionen, die wir im Datenreife-Check konkret abfragen:
| Dimension | Prüffrage | Typisches Ergebnis im Mittelstand |
|---|---|---|
| Vollständigkeit | Sind alle Felder befüllt? Fehlen Werte systematisch? | Kundenstamm oft 60–80 % vollständig, historische Transaktionen lückenhaft |
| Aktualität | Wie alt sind die Daten im System? Gibt es Verzögerungen? | ERP-Daten tagesaktuell, Excel-Exporte oft Wochen alt |
| Konsistenz | Stimmen doppelt gepflegte Daten überein? | Kunde A in ERP = anderes Format als in CRM |
| Zugriffsfähigkeit | Wer darf auf welche Daten? Sind Schnittstellen vorhanden? | BI-Anbindung vorhanden, aber kein Echtzeit-Zugriff für KI |
Ein typisches Ergebnis sieht dann so aus: „Für den Use Case Natural Language Queries sind die Vertriebsdaten in Ordnung. Für Predictive Maintenance fehlt ein Drittel der Maschinendaten aus dem MES. Für die Vertragsanalyse sind die Daten aus Datenschutzgründen aktuell nicht nutzbar.”
Genau diese Ehrlichkeit ist der Startpunkt.
Schritt 3, Single Point of Truth definieren: Nicht ersetzen, sondern konsolidieren
Ein Single Point of Truth bedeutet nicht, alle bestehenden Systeme zu ersetzen. Es bedeutet:
- Klare Master-Zuordnung: Welche Datenquelle liefert die verbindliche Information für welches Themenfeld?
- Konsolidierungsregeln: Was passiert, wenn zwei Systeme unterschiedliche Werte liefern?
- Zugriffsmechanismus: Wie greifen Reporting, Steuerung und KI auf dieselbe Quelle zu?
Beispiel: Ein Unternehmen mit ERP (SAP), CRM (HubSpot) und MES hatte drei unterschiedliche Definitionen von „Auftrag”. Monatlich wurden 6–8 Stunden damit verbracht, die Zahlen für die Geschäftsführung zu reconcilieren. Nach Einführung eines konsolidierten Datenmodells mit eindeutigen Felddefinitionen sank dieser Aufwand auf unter 1 Stunde pro Monat. Das ist der wirtschaftliche Hebel.
Schritt 4, Priorisierte Use Cases mit Datenbezug definieren
Datenstrategie und KI-Strategie werden parallel entwickelt. Der Unterschied: Sie starten nicht mit der Technologiefrage, sondern mit der Frage „Welches Geschäftsproblem hat die größte Auswirkung, wenn wir es datenbasiert lösen?”
Typische Einstiegs-Use-Cases für den Mittelstand, die auf einer soliden Datenstrategie aufbauen:
KPI-Natural-Language-Abfrage Fachbereiche und Management greifen auf relevante Zahlen, Abweichungen und Zusammenhänge zu, ohne auf einzelne Reports oder Spezialwissen angewiesen zu sein. Typisches Ergebnis: 60–80 % schnellere Antwortzeit auf KPI-Fragen. Voraussetzung: Ein konsolidiertes Datenmodell mit klaren Definitionen für alle relevanten Kennzahlen.
Automatisierte Dokumenten- und Vertragsanalyse Strukturierte Extraktion relevanter Informationen aus Verträgen, Rechnungen oder technischen Dokumenten. Typisches Ergebnis: Sachbearbeiter sparen 40–60 % der Zeit für wiederkehrende Dokumentenprüfung. Voraussetzung: Saubere Datengrundlage, konsistente Dokumentenformate.
Internes Wissensmanagement mit KI Unternehmensinternes Wissen wird für Mitarbeitende schneller und gezielter nutzbar. Typisches Ergebnis: Suchaufwand sinkt von ø 25 Min auf unter 3 Min pro fachlicher Frage. Voraussetzung: Klare Datenhoheit, strukturierte und bereinigte Wissensbestände.
Was das für Ihre Investitionsentscheidung bedeutet
Bevor Sie einen Berater beauftragen oder ein Tool auswählen, beantworten Sie drei Fragen:
1. Haben wir eine Bestandsaufnahme unserer relevanten Datenquellen? Wenn nein: Dieser Schritt kommt vor allem anderen.
2. Können wir die Datenqualität für unseren Ziel-Use-Case realistisch einschätzen? Wenn unsicher: Ein kurzes Datenqualitäts-Audit (1–2 Wochen) spart in der Regel Monate an Fehlentwicklungen.
3. Gibt es einen klaren Single Point of Truth für die Daten, die wir brauchen? Wenn nein: Das ist kein Hindernis, aber es muss als separates Arbeitpaket auf der Roadmap stehen, nicht als Appendix.
Unternehmen, die diese Fragen ehrlich beantworten, treffen bessere Entscheidungen über den Umfang, das Budget und den Zeitplan ihrer KI-Einführung.
FAQ: Häufige Fragen zur Datenstrategie vor KI
Müssen unsere Daten erst perfekt sein, bevor wir KI einsetzen können?
Nein. Perfektion ist weder realistisch noch nötig. Was Sie brauchen: eine ehrliche Einschätzung, ob die Datenqualität für den spezifischen Use Case ausreicht, den Sie starten wollen. Für den ersten Use Case reicht oft ein Durchschnittsniveau, wenn Sie es kennen und adressieren. Ein aufwendiges Master-Data-Management-Projekt vorab ist selten der richtige Einstieg.
Wie lange dauert es, eine Datenstrategie aufzubauen?
Eine fokussierte Bestandsaufnahme mit Bewertung der wichtigsten Datenquellen ist in zwei bis drei Wochen machbar. Ein vollständiger SPOT-Aufbau über mehrere Systeme hinweg kann drei bis neun Monate dauern, je nach Ausgangslage und Umfang. Beginnen Sie nicht mit dem Gesamtbild. Starten Sie mit den Daten für den wichtigsten Use Case.
Wir haben bereits ein BI-System. Reicht das nicht als Grundlage für KI?
Ein BI-System kann ein guter Ausgangspunkt sein, aber es ist nicht automatisch KI-fähig. BI-Systeme sind für vordefinierte Abfragen gebaut. KI braucht Daten in einer Form und Qualität, die oft über das hinausgeht, was ein Dashboard braucht. Prüfen Sie konkret: Entsprechen die Daten in Ihrem BI-System den Anforderungen des geplanten KI-Use-Cases?
Was ist der Unterschied zwischen Datenstrategie und Datenbasis-Aufbau?
Die Datenstrategie ist der Plan: Welche Daten haben wir, wie bewerten wir ihre Qualität, was wollen wir damit erreichen? Der Datenbasis-Aufbau ist die Umsetzung: Struktur schaffen, Konsolidierung herstellen, den SPOT bauen. Ohne Strategie wird der Aufbau ein Technologieprojekt ohne klares Ziel. Ohne Aufbau bleibt die Strategie ein Dokument ohne Substanz.
Können wir den Datenaufbau und die KI-Einführung parallel machen?
In der Praxis ja, aber mit der richtigen Priorisierung. Beginnen Sie mit dem Datenaufbau für den konkreten Use Case, den Sie starten wollen. Parallel können Sie die KI-Strategie und die Use-Case-Auswahl entwickeln. Was Sie nicht parallel machen sollten: einen KI-Piloten starten, ohne zu wissen, ob die Datenqualität dafür ausreicht.
Fazit
Die Datenstrategie kommt vor der KI-Strategie. Nicht, weil das ein schöner Methoden-Grundsatz ist, sondern weil die Erfahrung aus Dutzenden Projekten zeigt: KI-Projekte scheitern selten an der Technologie. Sie scheitern an den Daten.
Mittelständische Unternehmen, die diesen Zusammenhang ernst nehmen und vor einem ersten KI-Investment ein ehrliches Daten-Assessment durchführen, starten langsamer, und landen zuverlässiger.
Wenn Sie wissen wollen, wie es um Ihre Datenbasis bestellt ist und welche Schritte vor einem ersten KI-Projekt wirklich notwendig sind: Unser kostenloser Datenreife-Check gibt Ihnen in 5 Minuten eine erste Einschätzung. Oder Sie schauen sich direkt unseren Strategy Sprint an, zwei Wochen, senior-geführt, investitionsreife Entscheidungsvorlage.
